
ภูมิทัศน์ของการจัดการข้อมูลกำลังเปลี่ยนแปลงครั้งใหญ่ จากโลกของ data warehouse แบบ monolithic และ proprietary ไปสู่สถาปัตยกรรม data lakehouse แบบเปิด (open) และเชื่อมต่อกันได้ (interoperable) มากขึ้น หัวใจสำคัญของการเปลี่ยนผ่านนี้คือ Apache Iceberg™ ซึ่งเปิดโอกาสให้องค์กรสามารถใช้ compute engine ชั้นนำอย่าง Snowflake ทำงานบน “แหล่งข้อมูลเดียวที่ถูกกำกับดูแล (single, governed copy of data)” ได้อย่างมีประสิทธิภาพ
อย่างไรก็ตาม เมื่อองค์กรเริ่มนำแนวคิด open lakehouse มาใช้ ความท้าทายทางวิศวกรรมที่สำคัญก็เกิดขึ้นทันที นั่นคือ
เราจะเชื่อมต่อ data stack แบบเปิดใหม่นี้ เข้ากับ data platform เดิมที่มีอยู่ได้อย่างไร?
ปัญหานี้ไม่ใช่แค่เรื่องของ state management แต่เป็นเรื่องของ semantic mapping หรือการจับคู่ความหมายของโครงสร้างข้อมูล ระหว่าง
data lake model (เช่น catalog, namespace, table)
กับ
data warehouse model (เช่น database, schema, table)
ซึ่งมีแนวคิดการออกแบบที่ต่างกันโดยสิ้นเชิง
จากการวิเคราะห์ความต้องการของลูกค้า เราพบว่ามีความต้องการที่ “ถูกต้องทั้งคู่” แต่แตกต่างกันทางเทคนิคอย่างชัดเจน บทความนี้จึงอธิบายว่า Snowflake แก้โจทย์ semantic-mapping ที่ซับซ้อนนี้อย่างไร ด้วยการสร้างโซลูชันออกมา 2 แนวทาง ได้แก่
per-table link สำหรับ use case เชิง tactical
catalog linked database สำหรับ use case เชิง strategic ที่ต้อง map data lake ทั้งระบบ
ความท้าทายด้าน semantic mapping: Data lake vs. Data warehouse
ต้นตอของปัญหานี้มาจากแนวคิดการออกแบบการจัดการข้อมูลที่แตกต่างกัน แต่ล้วน “ถูกต้อง” ในบริบทของตัวเอง
Data lake-native model
ในโลกของ data lake เครื่องมืออย่าง Spark ถูกออกแบบให้เป็น stateless โดยอาศัย external catalog (เช่น Hive Metastore หรือ AWS Glue) เป็นแหล่งอ้างอิงหลัก (source of truth)
แนวคิดเรื่อง namespace (หรือ database) ใน catalog คือหน่วยหลักในการจัดระเบียบข้อมูล โมเดลนี้เหมาะมากกับความยืดหยุ่นและการใช้งานหลาย engine พร้อมกัน (multi-engine strategy) แต่แลกมากับการควบคุมด้าน performance และ data consistency ที่เข้มงวดน้อยกว่า warehouse
Warehouse-native model
ในฝั่งของ data warehouse แบบดั้งเดิม ตัวแพลตฟอร์มเองคือ catalog
โครงสร้าง database → schema → table เป็น source of truth โดยตรง ทำให้เกิดการผสานรวมที่แน่นหนา มี governance ที่ชัดเจน และรองรับ transactional consistency ได้ดี
เมื่อ warehouse ต้องเข้าถึงข้อมูลภายนอก มักใช้แนวคิดของ external table หรือ federated table
ความไม่สอดคล้องของโครงสร้าง (Structural mismatch)
อีกประเด็นสำคัญคือรูปแบบการจัดลำดับชั้นของข้อมูล
dedata lake catalog (เช่น Apache Iceberg catalog) รองรับ namespace แบบซ้อนลึกได้ไม่จำกัด
แต่ data warehouse อย่าง Snowflake มีโครงสร้างคงที่เพียง 2 ระดับ (database → schema)
โจทย์จึงกลายเป็นว่า จะนำโครงสร้าง data lake ที่ลึกและซับซ้อน มาแทนใน warehouse ที่แบนกว่าได้อย่างไร โดยไม่สูญเสียความหมายหรือความสามารถในการ scale
แนวคิดของ external table หรือการ link แบบรายตาราง ถูกออกแบบมาเพื่อการ query แบบเฉพาะกิจ (tactical) ซึ่งทำงานได้ดีในกรณีนั้น แต่ไม่เหมาะกับการ map ทั้ง namespace หรือทั้ง catalog
องค์กรที่ต้องจัดการ table จำนวนมาก (เช่น หลายพัน table) จะเจอปัญหา scalability ต้อง sync เอง และจัดการ lifecycle ที่ซับซ้อน
ความต้องการของลูกค้า 2 ระดับที่แตกต่างกัน
จากความแตกต่างด้าน design philosophy นี้ ทำให้ Snowflake มองเห็นความต้องการของผู้ใช้ 2 กลุ่มหลัก ซึ่งต้องแก้ให้ได้ทั้งคู่
Tactical need
นัก data scientist หรือ analyst ต้องการแค่เชื่อม ตารางเดียว (เช่น telemetry data จาก Spark) เข้ามาใน Snowflake database เดิม
ไม่ต้องการ database ใหม่ แค่ pointer ก็พอ
พวกเขายังทำงานอยู่ใน “warehouse model” และต้องการเพียงขยายความสามารถเล็กน้อย
Strategic need
ทีม data platform ต้องการ mirror ทั้ง data lake catalog (เช่น AWS Glue ที่มีหลายพัน table) ให้ใช้งานใน Snowflake ได้แบบครบถ้วน
ต้องการ mapping แบบ data lake-native ที่เมื่อมีการเปลี่ยนแปลงฝั่งหนึ่ง อีกฝั่งจะเข้าใจและสะท้อนผลโดยอัตโนมัติ
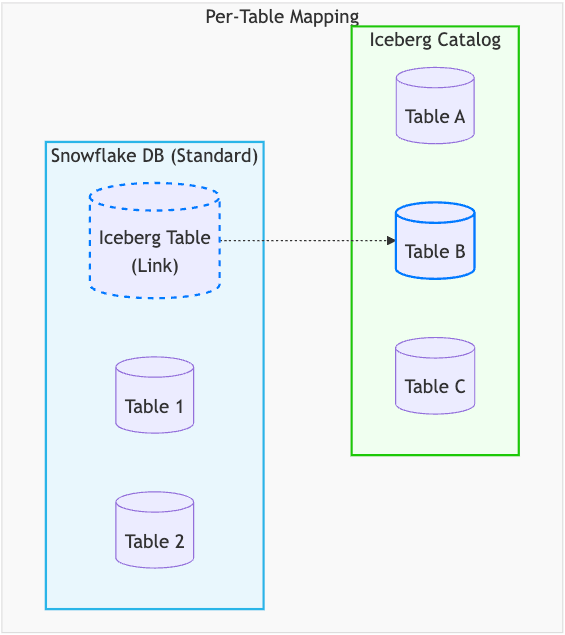
Tactical link: การ map แบบรายตาราง (Per-table mapping)
สำหรับความต้องการเชิง tactical Snowflake เลือกใช้แนวคิด shallow mapping ที่เรียบง่าย แต่เสริมความแข็งแกร่งด้านวิศวกรรมเข้าไป
แนวทางนี้ใช้คำสั่ง
CREATE ICEBERG TABLE
โดยระบุ parameter อย่าง CATALOG และ CATALOG_TABLE_NAME เพื่อสร้าง link แบบชัดเจนไปยัง Iceberg table ที่มีอยู่แล้วใน external catalog
วิธีนี้เหมาะอย่างยิ่งสำหรับ analyst ที่ต้องการเพิ่ม data lake table บางส่วนเข้ามาใน database เดิม
หัวใจทางวิศวกรรม
Snowflake แก้ปัญหาหลักด้วยการ overlay metadata layer ของ Snowflake ลงบน Iceberg table
ผลลัพธ์คือ:
ดึงโครงสร้างและ statistics ของ Iceberg table เข้าสู่ metadata system ของ Snowflake
optimizer สามารถวางแผน query และทำ data pruning ได้รวดเร็วเหมือน table native
ลด latency และค่าใช้จ่าย จากการไม่ต้อง fetch metadata ทุก query
โมเดลนี้เป็นแบบ “pay once” โดย metadata จะถูก refresh ผ่าน serverless process เท่านั้น ไม่ใช่ทุกครั้งที่ query
นอกจากนี้ linked table จะกลายเป็น first-class citizen ใน Snowflake สามารถใช้ governance, security และ ecosystem ต่าง ๆ ได้ครบถ้วน
Snowflake table ในกรณีนี้ทำหน้าที่เป็น link ไปยัง Iceberg table ภายนอก พร้อมกลไก serverless polling ที่คอย sync state ให้ทันสมัยอยู่เสมอ
ที่สำคัญ lifecycle ถูกแยกออกจากกันอย่างชัดเจน การ DROP TABLE ใน Snowflake จะเป็นแค่การยกเลิกการเชื่อมโยง ไม่ได้ลบ table ใน external catalog แต่อย่างใด
ทั้งหมดนี้คือการออกแบบที่ตั้งใจให้ตอบโจทย์การใช้งานจริง ทั้งด้านความยืดหยุ่น ประสิทธิภาพ และการควบคุมในระดับองค์กร โดยไม่ฝืนธรรมชาติของทั้ง data lake และ data warehouse ในเวลาเดียวกัน
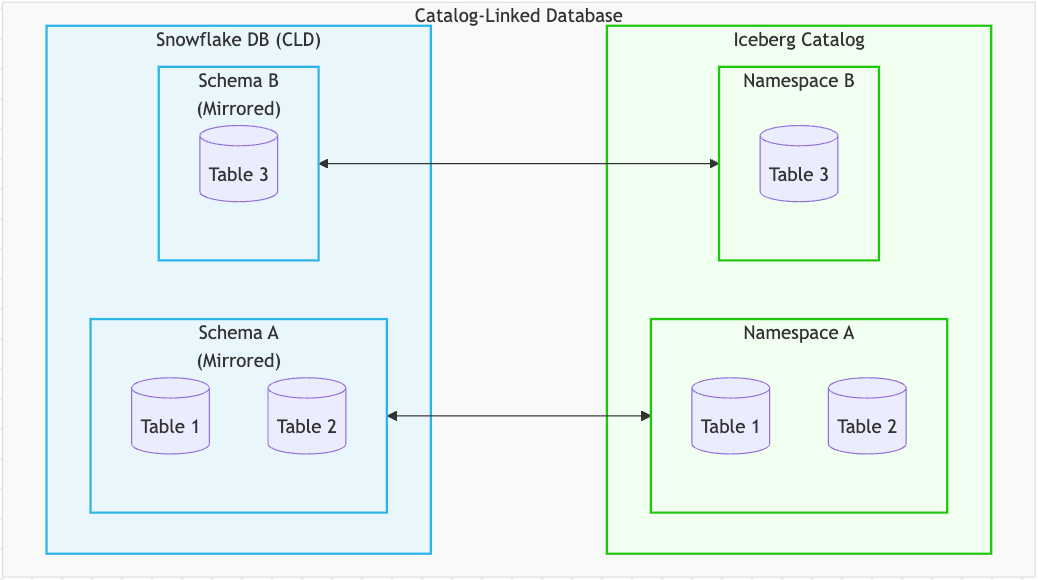
Strategic mirror: Catalog-Linked Database (CLD)
สำหรับความต้องการในเชิง strategic นั้น Snowflake ได้พัฒนาโซลูชันที่รองรับการทำ federation ขนาดใหญ่แบบอัตโนมัติ ด้วยการทำ semantic mapping เชิงลึก (deep semantic mapping) ที่เรียกว่า Catalog-Linked Database (CLD) โซลูชันนี้ถูกออกแบบมาสำหรับทีม data platform ที่ต้องการกระจกสะท้อน (mirror) ของ data lake ทั้งระบบ ซึ่งต้อง scale ได้, ทำงานอัตโนมัติ และมีความหมายเชิงโครงสร้างเทียบเท่ากัน กับ data lake เดิม
CLD คือการแทนค่า external catalog ให้อยู่ในรูปแบบที่เป็น warehouse-native อย่างแท้จริง ความท้าทายทางวิศวกรรมที่สำคัญคือการสร้าง bidirectional proxy ที่สามารถจับคู่ความหมายของทั้งสองโมเดลได้อย่างตรงกัน
Snowflake SCHEMA เทียบเท่ากับ external NAMESPACE
Snowflake TABLE เทียบเท่ากับ external TABLE
ความเทียบเท่าทาง semantic นี้หมายความว่า ทุก action ที่เกิดขึ้นในฝั่ง warehouse (เช่น การสร้าง table, การ rename, การสร้างหรือลบ schema เป็นต้น) จะต้องสามารถแปลงความหมายและสะท้อนผลไปยังฝั่ง data lake ได้อย่างชัดเจน และในทางกลับกันเช่นเดียวกัน
การแก้ปัญหา namespace ที่ไม่สอดคล้องกัน
เพื่อจัดการกับความแตกต่างของโครงสร้าง namespace Snowflake ใช้กลยุทธ์ที่เรียกว่า “flattening” โดยควบคุมผ่าน parameter อย่าง NAMESPACE_MODE และ NAMESPACE_FLATTEN_DELIMITER ในขั้นตอนการสร้าง CLD
แนวคิดคือ:
Snowflake schema จะถูก map ไปยัง external namespace ที่ถูก flatten แล้ว
ตัวอย่างเช่น หาก catalog มี namespace A และภายในมี namespace ซ้อนชื่อ B
Snowflake จะสร้าง schema ขึ้นมา 2 ตัวคือ A และ A.B เพื่อแทนทั้งสองระดับของ namespace
แนวคิดนี้สามารถขยายได้กับ namespace ที่ซ้อนลึกในระดับใดก็ได้ โดยยังคงความหมายเดิมของโครงสร้าง data lake ไว้อย่างครบถ้วน
Lifecycle ที่ซิงก์กันแบบสองทางอย่างสมบูรณ์
เมื่อ semantic equivalence ถูกสร้างขึ้นแล้ว ปัญหาเรื่อง state management จะกลายเป็นเรื่องที่ง่ายลงอย่างมาก Snowflake จึงสร้าง bidirectional synchronization engine ที่ทำงานต่อเนื่องและจัดการ lifecycle ทั้งหมดแบบอัตโนมัติ
นี่ไม่ใช่แค่การเปิดดูข้อมูลแบบ read-only แต่เป็นการเชื่อมต่อสองทางที่ active และมี lifecycle ที่ซิงก์กันเต็มรูปแบบ โดยประกอบด้วยความสามารถหลักดังนี้
Automatic discovery & refresh
namespace และ table ใหม่ที่ถูกสร้างจากภายนอก (เช่น โดย Spark job) จะถูกตรวจพบโดยอัตโนมัติ และปรากฏเป็น schema และ table ใน CLD ทันที รวมถึงการเปลี่ยนแปลงข้อมูลฝั่ง external ที่จะถูก sync เข้ามาเป็นระยะ
Full schema evolution
เมื่อมีการเพิ่ม column หรือเปลี่ยนชนิดข้อมูลใน catalog ระบบจะตรวจจับและอัปเดต definition ของ table ใน Snowflake ให้อัตโนมัติ
Bidirectional DDL / DML
คำสั่งอย่าง CREATE TABLE หรือ INSERT ที่ทำใน CLD จะถูก execute ไปยัง external catalog โดยตรง ทำให้ table นั้นพร้อมใช้งานกับ engine อื่น ๆ เช่น Spark ได้ทันที
ในทำนองเดียวกัน การ DROP TABLE ใน CLD จะลบ table ออกจาก catalog และถ้าลบจากฝั่ง catalog ก็จะสะท้อนกลับมาที่ CLD เช่นกัน วงจรชีวิตที่ซิงก์กันนี้คือ จุดแตกต่างที่สำคัญที่สุด ของ CLD
แนวคิดของ deep semantic mapping นี้ช่วยแก้ปัญหาเรื่อง scalability ได้ตรงจุด ด้วยการตัดขั้นตอน manual ออกไป และทำให้ทั้ง data lake model และ warehouse model ถูกดูแลให้ สอดคล้องกันอย่างต่อเนื่อง โดยอัตโนมัติ แม้ในสภาพแวดล้อมที่มีข้อมูลจำนวนมากและซับซ้อนระดับองค์กร
นี่คือคำแปลของข้อความดังกล่าว โดยใช้ภาษาไทยแบบทางการกึ่งเทคนิค และใช้คำทับศัพท์ในคำศัพท์เฉพาะทางเพื่อให้เข้าใจได้ง่ายสำหรับคนทำงานสาย Data ครับ
The Strategic Mirror (Catalog-Linked Database)
เพื่อตอบโจทย์ความต้องการเชิงกลยุทธ์ เราได้สร้างโซลูชัน Deep Semantic Mapping (การเชื่อมโยงข้อมูลเชิงความหมายระดับลึก) สำหรับการทำ Automated Federation ในสเกลใหญ่ นั่นคือ Catalog-Linked Database (CLD)
โซลูชันนี้ออกแบบมาเพื่อทีม Platform ที่ต้องการ Mirror (ภาพสะท้อนข้อมูล) ของ Data Lake ที่สามารถ Scale ได้ เป็นระบบอัตโนมัติ และมีความเท่าเทียมกันในเชิงความหมาย (Semantically Equivalent)
แนวคิดหลักและการทำงาน (Core Concept)
CLD คือตัวแทนของ External Catalog ในรูปแบบ Warehouse-native ความสำเร็จทางวิศวกรรมในที่นี้คือการสร้าง Proxy แบบสองทิศทาง (Bidirectional Proxy) ที่ทำให้ Data Model ของทั้งสองฝั่งมีความหมายเท่าเทียมกัน:
Snowflake SCHEMA คือ External NAMESPACE
Snowflake TABLE คือ External TABLE
ความเท่าเทียมกันนี้หมายความว่า ทุกการกระทำ (เช่น การสร้าง Table, การเปลี่ยนชื่อ, การสร้าง/ลบ Schema ฯลฯ) ในฝั่ง Warehouse จะสามารถแปลความหมายไปยังฝั่ง Data Lake ได้อย่างชัดเจนและถูกต้อง (และในทางกลับกัน)
การจัดการลำดับชั้นข้อมูล (Flattening Strategy)
เพื่อแก้ปัญหาความไม่ตรงกันของโครงสร้างลำดับชั้น (Namespace Hierarchy Mismatch) เราใช้กลยุทธ์ "Flattening" (การเกลี่ยโครงสร้างให้แบนราบ) ซึ่งควบคุมโดยพารามิเตอร์อย่าง NAMESPACE_MODE และ NAMESPACE_FLATTEN_DELIMITER ในขณะสร้าง CLD
Schema ของ Snowflake จะถูก Map เข้ากับ External Namespace ที่ถูก Flatten แล้ว ยกตัวอย่างเช่น:
หาก Catalog มี Namespace A ที่มี Namespace B ซ้อนอยู่ข้างใน -> Snowflake จะสร้าง Schema ขึ้นมาสองอันคือ A และ A.B เพื่อเป็นตัวแทนของ Namespace ทั้งสองระดับ (คอนเซปต์นี้สามารถรองรับความลึกของชั้นข้อมูลได้ไม่จำกัด)
การซิงค์ข้อมูลและ Lifecycle (Synchronization Engine)
เมื่อความเท่าเทียมกันเชิงความหมายถูกสร้างขึ้น การจัดการ State ก็กลายเป็นเรื่องง่ายขึ้นมาก เราได้สร้าง Synchronization Engine แบบต่อเนื่องสองทิศทาง (Continuous, Bidirectional) ที่จัดการ Lifecycle ทั้งหมดแบบอัตโนมัติ นี่ไม่ใช่แค่ View แบบ Read-only แต่เป็นการ Integration แบบ Active ทั้งสองฝั่งที่มี Lifecycle เชื่อมถึงกันอย่างสมบูรณ์:
Automatic Discovery and Refresh: Namespace และ Table ใหม่ที่ถูกสร้างจากภายนอก (เช่น โดย Spark Job) จะถูกค้นพบและปรากฏเป็น Schema และ Table ใน CLD โดยอัตโนมัติ ในทำนองเดียวกัน การเปลี่ยนแปลงที่เกิดกับ Table ภายนอกก็จะถูก Sync เข้ามาเป็นระยะๆ
Full Schema Evolution: การเพิ่ม Column หรือการเปลี่ยน Type ใน Catalog จะถูกตรวจจับและอัปเดตใน Definition ของ Snowflake Table โดยอัตโนมัติ
Bidirectional DDL/DML: คำสั่ง CREATE TABLE หรือ INSERT ที่ทำภายใน CLD จะถูกดำเนินการกับ External Catalog ด้วย ทำให้ Table นั้นพร้อมใช้งานสำหรับ Engine อื่นๆ (เช่น Spark) ทันที ในขณะที่คำสั่ง DROP TABLE ใน CLD ก็จะลบ Table ออกจาก Catalog เช่นกัน ซึ่ง Lifecycle ที่เชื่อมโยงกันนี้คือจุดเด่นที่สร้างความแตกต่าง
โดยสรุป "Deep Semantic Mapping" นี้ช่วยแก้ปัญหาเรื่อง Scalability โดยการตัดขั้นตอนการทำงานแบบ Manual ออกไป และช่วยให้มั่นใจได้ว่าโมเดลทั้งสองฝั่งจะถูก Sync ให้ตรงกันอยู่ตลอดเวลา
ต้องการให้ผมช่วยขยายความส่วนไหนเพิ่มเติม หรืออธิบายคำศัพท์เทคนิคคำไหนเจาะจงไหมครับ?
ตารางเปรียบเทียบ: Per-table mapping vs. Catalog-linked database
| ฟีเจอร์ (Feature) | Per-table mapping (Standard Database) | Catalog-linked database (CLD) |
| หน่วยของการ Integration | External Table รายตัว | ทั้ง Catalog โดยมีการกำหนดขอบเขตย่อยระดับ Namespace |
| Catalog ที่รองรับ | OBJECT_STORE, GLUE, ICEBERG_REST (Polaris, AWS Glue, Unity, ฯลฯ) | ICEBERG_REST (Polaris, AWS Glue, Unity, ฯลฯ) |
| รูปแบบการติดตั้ง (Setup Model) | Imperative: ต้องสั่ง CREATE ICEBERG TABLE สำหรับแต่ละ Table | Declarative: สั่ง CREATE DATABASE เพียงครั้งเดียวเพื่อเชื่อมโยงทุก Table ใน Namespace(s) |
| การจัดการ Lifecycle | แยกขาดจากกัน (Decoupled): คำสั่ง DROP TABLE ใน Snowflake จะเป็นเพียงการยกเลิกการเชื่อมโยง (Unlink) เท่านั้น การสร้าง Table ใหม่จะเป็นแบบ Link-only และการเปลี่ยนชื่อ Table ใน Remote Catalog จะไม่ส่งผลมาที่ Snowflake | เชื่อมโยงกัน (Synchronized): คำสั่ง DROP TABLE ใน Snowflake จะลบ Table ออกจาก Catalog จริงๆ การเปลี่ยนแปลงภายนอก (สร้าง, ลบ, เปลี่ยนชื่อ) จะถูก Propagate มาโดยอัตโนมัติ |
| Scalability | ต่ำ: เหมาะสำหรับจำนวน Table น้อยๆ และไม่ค่อยเปลี่ยนแปลง ต้องใช้แรงงานเยอะ (Operationally intensive) เมื่อสเกลใหญ่ขึ้น | สูง: ออกแบบมาเพื่อจัดการ Table หลักร้อยหรือหลักพันได้โดยอัตโนมัติ |
| การ Sync Metadata | ระดับ Table: เปิดใช้งานผ่าน AUTO_REFRESH = TRUE | ระดับ Database: มีการ Polling ต่อเนื่องตามค่า SYNC_INTERVAL_SECONDS เพื่อค้นหา Schema/Table อัตโนมัติ และใช้ REFRESH_INTERVAL_SECONDS เพื่อรีเฟรช Metadata ระดับ Table |
บทสรุป (Conclusion)
ด้วยการสร้างโมเดลที่แตกต่างแต่ส่งเสริมกัน 2 รูปแบบ ได้แก่ โมเดลแบบ Link-based ที่เรียบง่าย สำหรับความต้องการเชิง Tactical (การแก้ปัญหาเฉพาะหน้า) และ Deep Semantic Proxy สำหรับสเกลระดับ Strategic (กลยุทธ์ระยะยาว) เราจึงได้สร้าง Platform ที่ยืดหยุ่นและตอบโจทย์ผู้ใช้งานได้อย่างตรงจุด
แนวทางนี้ช่วยแก้ปัญหาเรื่อง "Mapping Dilemma" โดยมอบจุดเริ่มต้นที่ง่ายดายสำหรับ Analyst และมอบโซลูชันที่ทรงพลัง เป็นอัตโนมัติ และถูกต้องตามหลัก Semantic สำหรับทีม Platform วิธีการนี้ช่วยปลดล็อก Data Engineer จากภาระการจัดการ Metadata Drift ด้วยมือ และช่วยให้พวกเขาสามารถสร้าง Single Source of Truth ที่เชื่อถือได้ เพื่อให้บริการผู้ใช้งานทุกคน ตั้งแต่งาน Data Science เชิง Tactical ไปจนถึงงาน Analytics ระดับ Platform เชิง Strategic
ขอบคุณบทความต้นฉบับบจาก Snow flake
เรื่อง "Bringing the Snowflake Platform to Data Lakes"
ผู้เขียน
Maninderjit Parmar
Data Engineering