
โรงงานสมัยใหม่ไม่ได้ขาดข้อมูล — แต่ขาด ที่เก็บข้อมูลที่รวมทุกอย่างไว้ด้วยกัน ข้อมูลจากเซ็นเซอร์, ระบบ ERP, ไลน์การผลิต, และ QC กระจัดกระจายอยู่คนละระบบ ทำให้วิเคราะห์ได้ยาก ช้า และไม่ครบถ้วน Data Lake คือคำตอบที่ช่วยให้โรงงานรวม Factory Data ไว้ใน Cloud Storage เดียว พร้อมเปิดประตูสู่ Big Data Analytics อย่างเต็มรูปแบบ
Data Lake คืออะไร? ทำไมโรงงานถึงต้องการ
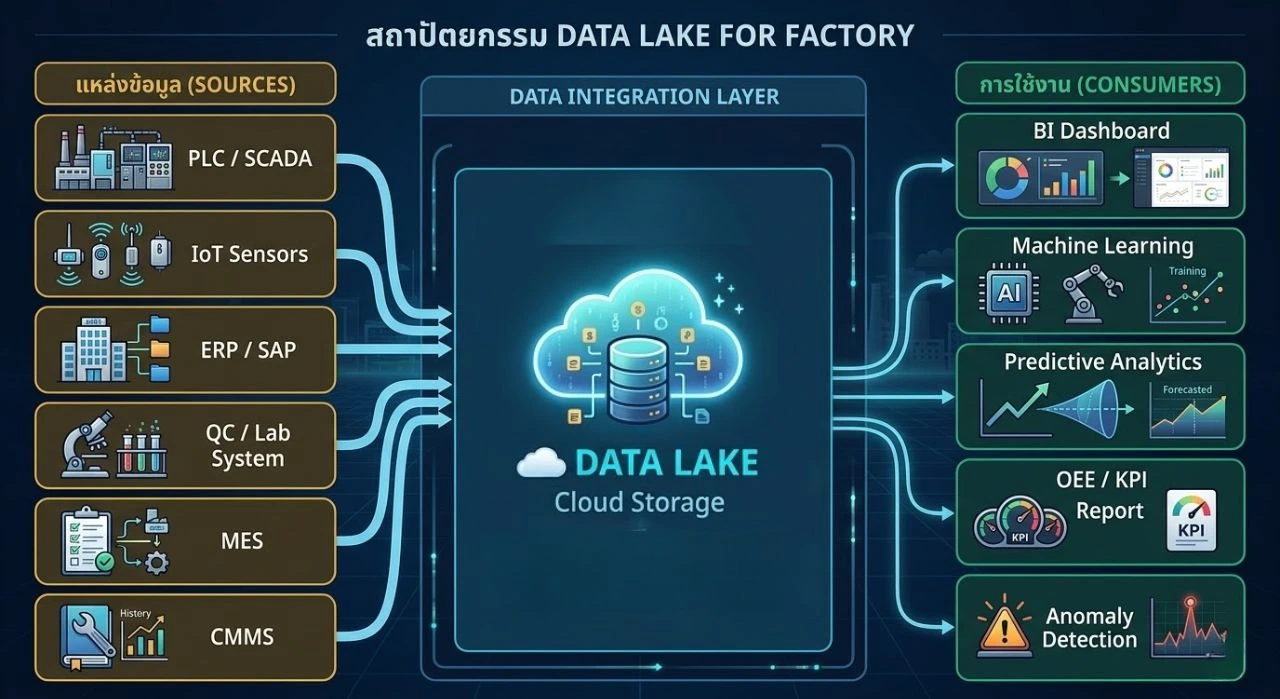
Data Lake คือระบบเก็บข้อมูลขนาดใหญ่แบบรวมศูนย์ที่รับข้อมูลได้ทุกรูปแบบ ไม่ว่าจะเป็น Structured (ตาราง SQL), Semi-structured (JSON, XML) หรือ Unstructured (ภาพ, เสียง, ไฟล์ log) โดยเก็บข้อมูลในรูปแบบดั้งเดิม (Raw Format) ก่อน แล้วค่อยแปลงเมื่อต้องนำไปใช้งาน ต่างจาก Data Warehouse ที่ต้องกำหนดโครงสร้างก่อนนำเข้า
สำหรับ Factory Data โดยเฉพาะ Data Lake เปรียบเหมือนทะเลสาบขนาดใหญ่ที่รับน้ำจากแม่น้ำหลายสาย ทั้งข้อมูล IoT Sensor ที่ส่งค่าทุก 100ms, log การผลิตที่สะสมทุกวัน, ข้อมูลคุณภาพจาก Lab, และรายการสั่งซื้อจาก ERP ทุกอย่างไหลมารวมกันที่เดียว พร้อมให้วิเคราะห์ทุกเมื่อ
Factory Data มาจากไหนบ้าง?
โรงงานผลิตขนาดกลาง–ใหญ่สร้างข้อมูลจากหลายแหล่งพร้อมกัน แต่ละแหล่งมีโครงสร้าง ความเร็ว และปริมาณที่แตกต่างกันมาก การเข้าใจแหล่งที่มาของข้อมูลคือจุดเริ่มต้นของ Data Integration ที่มีประสิทธิภาพ
- IoT Sensors & PLC — ข้อมูลอุณหภูมิ แรงดัน การสั่นสะเทือน ความเร็วรอบ ส่งขึ้นทุก 100ms–1 วินาที เป็น Streaming Data แบบ Real-time ปริมาณข้อมูลสูงมาก
- ERP System (SAP, Oracle) — ข้อมูลการสั่งซื้อ, BOM, inventory, ต้นทุนการผลิต เป็น Structured Data อัปเดตแบบ Batch รายวันหรือรายชั่วโมง
- MES (Manufacturing Execution System) — Log การผลิตแต่ละ lot, เวลาเริ่ม–หยุด, จำนวนชิ้นดี–เสีย เป็นแหล่งข้อมูลสำคัญสำหรับคำนวณ OEE
- QC & Lab Data — ผลการทดสอบคุณภาพ, SPC Chart, ค่าเบี่ยงเบน มักอยู่ใน Excel หรือระบบ LIMS แยกต่างหาก ต้องการ Data Integration เพื่อเชื่อมกับข้อมูลการผลิต
- CMMS / Maintenance Log — ประวัติการซ่อม, แผน PM, อายุชิ้นส่วน สำคัญมากสำหรับ Predictive Maintenance
- กล้องวงจรปิด / Vision AI — ภาพจากสายการผลิต, ผลการตรวจ defect ด้วย AI เป็น Unstructured Data ที่ต้องการ Cloud Storage รองรับไฟล์ขนาดใหญ่
Data Lake vs Data Warehouse: เลือกอะไรดีสำหรับโรงงาน
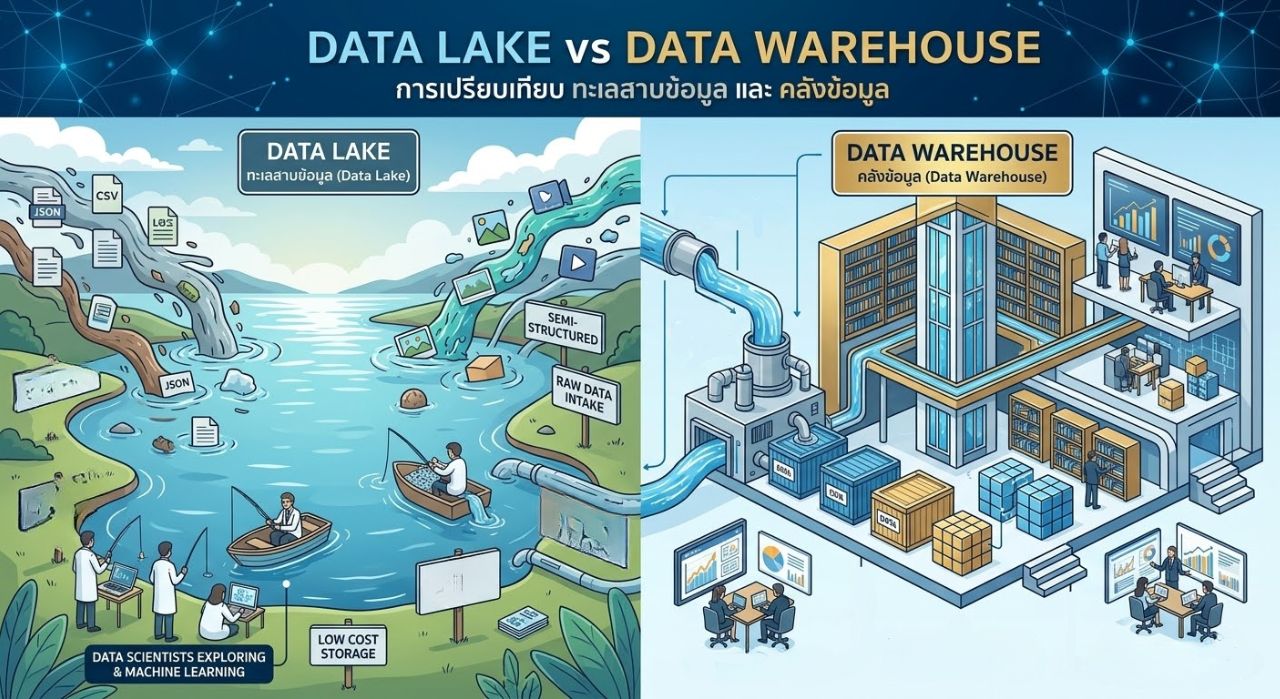
หลายองค์กรยังสับสนระหว่าง Data Lake และ Data Warehouse ทั้งสองมีจุดแข็งต่างกัน
Data Lake เหมาะกับข้อมูลทุกรูปแบบ ใช้ Schema-on-read (ยืดหยุ่น) ต้นทุน Storage ต่ำ เหมาะสำหรับ ML/AI และการเก็บ Sensor Streaming, Historical Log, Vision AI
Data Warehouse เหมาะกับ Structured Data เท่านั้น ใช้ Schema-on-write Query เร็วกว่าสำหรับรายงานที่มีโครงสร้างชัดเจน เหมาะสำหรับ Financial Report, KPI Dashboard
สำหรับโรงงานที่เพิ่งเริ่มต้น แนะนำให้ใช้ Data Lake เป็นศูนย์กลาง แล้วสร้าง Curated Zone ที่มีโครงสร้างเพื่อป้อนข้อมูลให้ BI Tools นี่คือแนวคิดของ Lakehouse Architecture ที่ได้ทั้งความยืดหยุ่นและความเร็วในการวิเคราะห์
Cloud Storage สำหรับ Data Lake: ตัวเลือกหลัก
Cloud Storage คือโครงสร้างพื้นฐานของ Data Lake สมัยใหม่ แทนที่จะลงทุนใน Server ราคาแพงภายในโรงงาน องค์กรสามารถใช้บริการ Object Storage บน Cloud ที่ scale ได้ไม่จำกัด จ่ายตามที่ใช้จริง และมี SLA ที่เชื่อถือได้
- Amazon (AWS) — Ecosystem ครบที่สุด รองรับ IoT ผ่าน AWS IoT Core เชื่อมกับ Glue/Athena ได้ทันที
- Snowflake — โดดเด่นเรื่องการทำ Data Lakehouse ที่รวมความยืดหยุ่นของ Data Lake เข้ากับความเร็วของ Data Warehouse
โรงงานที่มีข้อจำกัดด้านความปลอดภัยของข้อมูล อาจเลือกใช้ Hybrid Cloud โดยเก็บข้อมูลสำคัญไว้ On-premise และ Sync เฉพาะ Aggregated Data ขึ้น Public Cloud เพื่อลดความเสี่ยงและต้นทุน Bandwidth
Data Integration: หัวใจสำคัญของ Data Lake โรงงาน
Data Integration คือกระบวนการที่ท้าทายที่สุดในการสร้าง Data Lake สำหรับโรงงาน เพราะต้องรับมือกับโปรโตคอลที่หลากหลาย เช่น OPC-UA, Modbus, MQTT จาก IoT Devices, REST API จาก ERP, และไฟล์ CSV จาก Lab System
ขั้นตอนที่แนะนำมีดังนี้
- Data Source Discovery & Mapping — สำรวจและจัดทำ catalog ของแหล่งข้อมูลทั้งหมด ระบุโปรโตคอล ความถี่ และรูปแบบข้อมูลของแต่ละระบบ
- ETL / ELT Pipeline Design — ออกแบบ Pipeline สำหรับ Extract ข้อมูลจากแต่ละแหล่ง Load เข้า Data Lake แบบ Raw Zone ก่อน แล้วค่อย Transform ผ่าน Data Pipeline
- Real-time Streaming vs Batch Processing — ข้อมูล IoT Sensor ใช้ Streaming Pipeline (Apache Kafka, AWS Kinesis) ส่วนข้อมูล ERP ที่อัปเดตรายวันใช้ Batch Processing ด้วย Apache Spark หรือ dbt
- Data Quality & Governance — กำหนด Rule การตรวจสอบคุณภาพข้อมูล เช่น ค่า null ที่ยอมรับได้ range ของค่าเซ็นเซอร์ การ deduplicate
- Data Catalog & Metadata Management — สร้าง Catalog ที่บอกว่ามีข้อมูลอะไรบ้างใน Data Lake มาจากไหน อัปเดตล่าสุดเมื่อไหร่ และใครเป็นเจ้าของ
Big Data Analytics ที่โรงงานทำได้เมื่อมี Data Lake

เมื่อ Factory Data ทั้งหมดรวมอยู่ใน Data Lake แล้ว โรงงานสามารถปลดล็อก Big Data Analytics ที่ทรงพลังได้หลายมิติ
Predictive Maintenance — โดยการรวมข้อมูล Vibration Sensor, อุณหภูมิ Bearing, และประวัติการซ่อมจาก CMMS เข้าด้วยกัน ML Model สามารถทำนายได้ว่า Motor ตัวใดจะเสียภายใน 72 ชั่วโมง ลดการหยุดสายการผลิตฉุกเฉินได้ถึง 30–50%
Root Cause Analysis แบบ Multi-variable — เมื่อมีชิ้นงาน defect เพิ่มขึ้น ระบบสามารถ correlate พร้อมกันระหว่าง parameter ของเครื่อง, Lot วัตถุดิบ, กะการทำงาน และสภาพแวดล้อมโรงงาน ค้นพบสาเหตุที่แท้จริงได้เร็วกว่าการวิเคราะห์ด้วยมือหลายสัปดาห์
Energy Optimization — วิเคราะห์การใช้ไฟฟ้าของแต่ละเครื่องจักรเทียบกับ Production Output เพื่อระบุ "Energy Waste" และ Schedule งานในช่วง Off-peak
Supply Chain & Demand Forecasting — รวมข้อมูล Production History กับ Sales Forecast และ Lead Time ของ Supplier เพื่อ Optimize Inventory Level ลด Stockout และ Overstock ได้พร้อมกัน
เริ่มต้น Data Lake สำหรับโรงงานอย่างไรให้ได้ผล
ความผิดพลาดที่พบบ่อยที่สุดคือการพยายาม "เก็บทุกอย่างก่อน" โดยไม่มีเป้าหมายชัดเจน ทำให้ได้ "Data Swamp" แทน Data Lake แนวทางที่แนะนำคือเริ่มจาก Use Case ที่มี Business Value ชัดเจน แล้วค่อยขยาย
- เลือก 1–2 Use Case ที่มี ROI ชัดเจน เช่น Predictive Maintenance ของเครื่องจักรที่ Downtime แพงที่สุด
- Design Data Architecture ที่ Scale ได้ วางโครงสร้าง Zone ของ Data Lake (Raw → Bronze → Silver → Gold) ตั้งแต่แรก
- Pilot กับ Data Sources 3–5 แหล่งก่อน ทดสอบ Pipeline, Data Quality และ Latency ก่อน Scale ขึ้น
- สร้างทีม Data ภายในองค์กร ต้องการ Data Engineer, Data Analyst และ Data Steward ดูแลระบบอย่างต่อเนื่อง
- วัดผลและขยายต่อเนื่อง ใช้ความสำเร็จของ Use Case แรกเป็น Business Case สำหรับขยาย Data Lake ต่อไป
สรุป: Data Lake คือรากฐานของ Smart Factory
ใน Industry 4.0 Data Lake คือโครงสร้างพื้นฐานที่ขาดไม่ได้ การมี Cloud Storage ที่รวม Factory Data จากทุกแหล่งผ่าน Data Integration ที่แข็งแกร่ง เปิดประตูสู่ Big Data Analytics ที่ช่วยให้โรงงานตัดสินใจได้เร็วขึ้น แม่นยำขึ้น และลดต้นทุนได้อย่างวัดผลได้
โรงงานที่เริ่มต้น Data Lake วันนี้ไม่ได้แค่ "เก็บข้อมูล" แต่กำลังสร้าง Competitive Advantage ที่คู่แข่งยากจะตามทัน เพราะยิ่ง Data สะสมมากขึ้น Model ก็ยิ่งแม่นขึ้น และ Insight ก็ยิ่งมีคุณค่ามากขึ้น