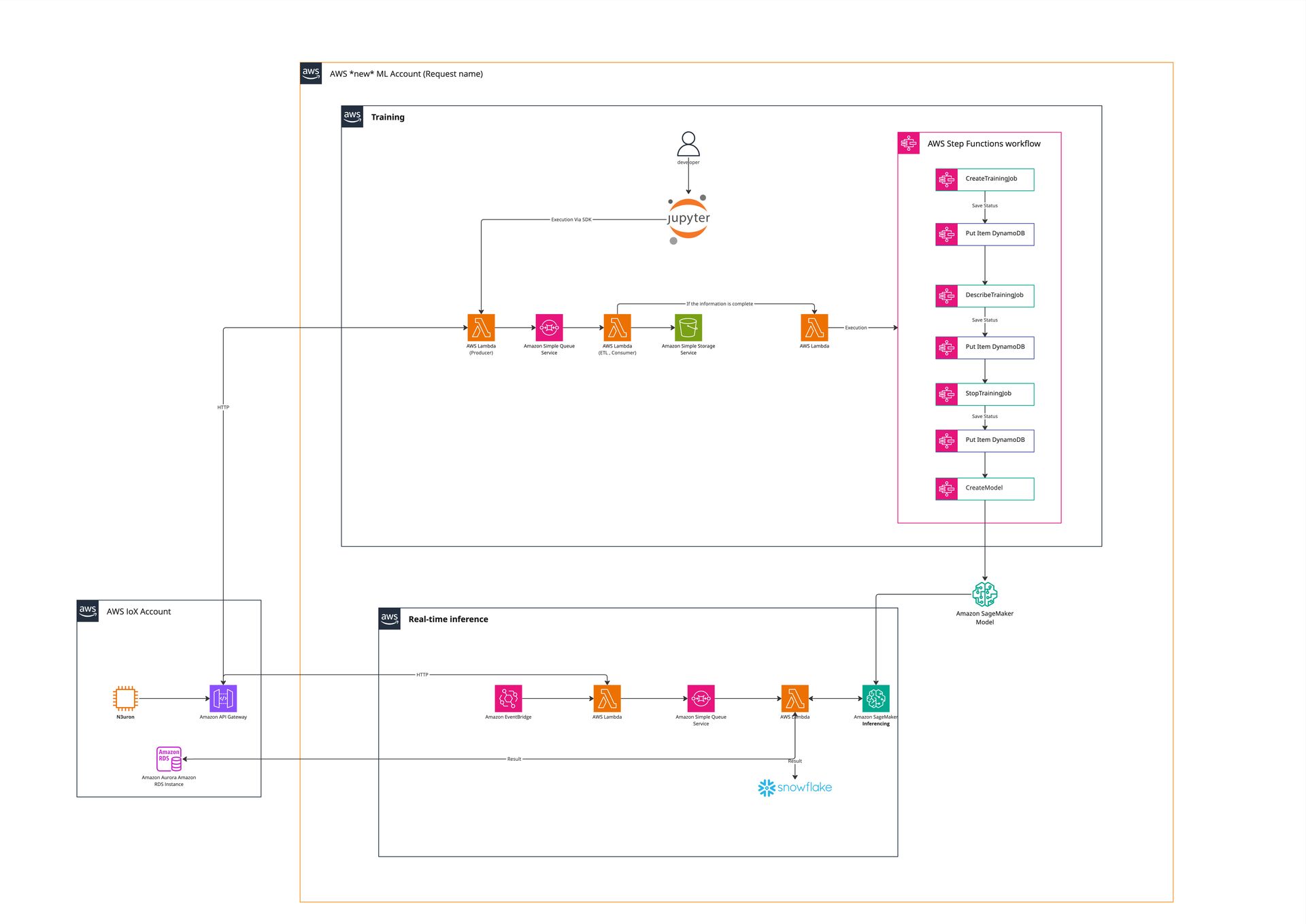
🧠 ส่วนที่ 1: Training (ฝึกสอนโมเดล)
✅ เป้าหมายของส่วนนี้
ดึงข้อมูลขนาดใหญ่จาก REST API
เตรียมข้อมูลและส่งให้ SageMaker Training Job
ติดตามสถานะ และจัดเก็บ Metadata ด้วย Step Functions + DynamoDB
🔹 โครงสร้างองค์ประกอบ (Component Breakdown)
| องค์ประกอบ | บทบาท |
|---|---|
| 🔶 Jupyter Notebook | จุดเริ่มต้นคำสั่งเทรนโดยนักพัฒนา |
| 🟧 Lambda: Job Distributor | สร้าง job list และส่งเข้า SQS เพื่อดึงข้อมูลจาก REST API |
| 🟪 Amazon SQS | เก็บรายการ “job ดึงข้อมูล” เพื่อให้ดึงทีละส่วน |
| 🟧 Lambda Worker | ค่อย ๆ ดึง job จาก SQS แล้วไปเรียก REST API |
| 🟩 Amazon S3 | เก็บข้อมูลดิบ (raw) ที่ดึงมา หรือข้อมูลที่เตรียมไว้ใช้ฝึกโมเดล |
| 🟧 Lambda Trigger | เรียก Step Function เพื่อเทรนโมเดล เมื่อข้อมูลพร้อมแล้ว |
| 🟪 AWS Step Functions | ควบคุม workflow ของการ Training |
| 🟥 Amazon DynamoDB | บันทึกสถานะ Training แต่ละขั้นตอน |
| 🧠 Amazon SageMaker | ฝึกโมเดลจากข้อมูลใน S3 |
🧩 อธิบายแต่ละส่วนเพิ่มเติม
🔸 Lambda: Job Distributor
แปลงคำสั่งจาก Jupyter → job list (แบ่ง page, time range)
ส่งแต่ละ job เข้าคิว SQS
🔸 SQS
ช่วย ควบคุมโหลด จากการดึง API
ให้ Lambda worker ดึงแบบ async/parallel
🔸 Lambda Worker
ดึง job จากคิว
ไปดึงข้อมูลจาก REST API → เก็บลง S3
เมื่อครบแล้ว ส่ง trigger ไปยัง Lambda ตัวถัดไป
🔸 Lambda Trigger Step Function
เมื่อข้อมูลครบ ส่ง signal เพื่อเริ่มเทรนโมเดล
เรียก AWS Step Functions
🔸 Step Functions
ควบคุมลำดับดังนี้:
CreateTrainingJob → เริ่ม Training บน SageMaker
PutItem DynamoDB → เก็บ metadata เช่น jobId, modelName
DescribeTrainingJob → เช็คสถานะระหว่าง Training
StopTrainingJob → ปิดการเทรนเมื่อครบเวลา หรือมีเงื่อนไข
CreateModel → deploy endpoint หลังเทรนเสร็จ
🔸 DynamoDB
ใช้เก็บข้อมูลสำคัญ เช่น
สถานะ training (Running, Completed, Failed)
เวลาเริ่ม/จบ
ชื่อโมเดล, dataset ID
สามารถใช้เช็คความคืบหน้าได้ภายหลัง
✅ สรุปเด่นของ Training Flow
| ด้าน | จุดเด่น |
|---|---|
| 🧱 ความยืดหยุ่น | ใช้ SQS แยกงานแบบ granular |
| 🚀 การควบคุม | ควบคุม Training flow ได้ครบถ้วนผ่าน Step Functions |
| 🔄 Fault Tolerance | ถ้า job ดึง API ล้มเหลว สามารถ retry ได้แบบ isolated |
| 📊 Tracking | DynamoDB บันทึกทุกขั้นตอน → ตรวจสอบย้อนหลังได้ |
| 📦 ข้อมูลพร้อมใช้ | เก็บข้อมูลไว้ใน S3 ใช้ได้ทั้ง Training และ Audit |
⚙️ ส่วนที่ 2: Real-time Inference (จาก N3uron → SageMaker → Snowflake)
✅ เป้าหมาย:
ดึงข้อมูลจากระบบภายนอก (N3uron ผ่าน API Gateway)
ประมวลผลผ่าน SageMaker Model แบบเรียลไทม์
ส่งผลลัพธ์ไปจัดเก็บใน Snowflake หรือแหล่งปลายทางอื่น ๆ
🔹 องค์ประกอบและบทบาท
| องค์ประกอบ | บทบาท |
|---|---|
| 🟧 N3uron | แหล่งข้อมูล IoT หรือ edge device |
| 🟪 Amazon API Gateway | รับข้อมูลจาก N3uron ผ่าน HTTP |
| 🟥 Amazon EventBridge | ใช้ Trigger การประมวลผลตาม event หรือเวลาที่กำหนด |
| 🟧 AWS Lambda (ตัวแรก) | รับข้อมูลจาก API / EventBridge แล้วแปลงเป็น message |
| 🟪 Amazon SQS | คิวสำหรับจัดการโหลดข้อมูลก่อนประมวลผล |
| 🟧 AWS Lambda (ตัวที่สอง) | อ่านจาก SQS → ส่งไป SageMaker |
| 🧠 SageMaker Model Endpoint | ทำ inference ด้วยโมเดล ML |
| 🟦 Amazon SageMaker Inferencing | Layer ที่รับและตอบผลลัพธ์ |
| 🟧 Lambda (post-process) | แปลงผลลัพธ์ และส่งออกปลายทาง |
| 🟦 Snowflake | เก็บผลลัพธ์สำหรับ dashboard / BI / วิเคราะห์ย้อนหลัง |
| 🟪 Amazon Aurora (RDS) | ฐานข้อมูลสำหรับ context หรือ lookup เสริม (เช่นข้อมูลผู้ใช้ / config) |
🧩 จุดเด่นเชิงเทคนิค
🔸 ใช้ API Gateway รับข้อมูลจาก N3uron
ปรับให้รับ HTTP POST → ปลอดภัย ควบคุมได้ด้วย Auth / Rate Limit
🔸 ใช้ EventBridge เสริมสำหรับ trigger ตามเวลา
เช่น ตรวจสอบข้อมูลทุก 1 นาที / 5 นาที
หรือดึงข้อมูล batch แทนแบบ push
🔸 ใช้ SQS เพื่อจัดการโหลดและ decouple
ป้องกัน overload จากการรับข้อมูลแบบ burst
เพิ่มความสามารถในการ scale Lambda reader แบบ parallel ได้
🔸 ใช้ SageMaker Endpoint สำหรับการพยากรณ์แบบทันที (real-time)
รับ input → ประมวลผลโมเดล → ส่ง output กลับ
🔸 ส่งผลลัพธ์ไป Snowflake , RDS
ใช้ทำ dashboard, anomaly monitoring, ฯลฯ
✅ สรุปจุดแข็งของ Real-time Inference Architecture นี้
| คุณสมบัติ | รายละเอียด |
|---|---|
| ⚡ ความเร็ว | ข้อมูลจาก N3uron ถึงผลลัพธ์ใช้เวลาไม่กี่วินาที |
| 🧩 Decoupled | Lambda + SQS ทำให้ system ทนต่อโหลดสูง |
| 📊 Data Lake Ready | เก็บผลลัพธ์ที่ Snowflake หรืออื่น ๆ ได้แบบ structured |
| 🔁 ปรับขยายง่าย | Lambda และ SQS scale ตามปริมาณข้อมูลแบบอัตโนมัติ |
| 🔐 ปลอดภัย | API Gateway และ EventBridge ช่วยควบคุม access ได้ดี |